MANZ Genjus KI: Die Zukunft der juristischen Recherche
Herausforderungen und Chancen bei der Datenaufbereitung
Juristische Texte sind komplex und detailliert. Sie enthalten nicht nur explizite Informationen, sondern oft auch eine Vielzahl impliziter Bedeutungen, die für ein tiefes Verständnis des Textes entscheidend sind. Die traditionelle Rechtsforschung erfordert daher ein hohes Maß an Aufmerksamkeit und Sorgfalt, um die relevanten Informationen zu extrahieren und korrekt zu interpretieren. Auch bei der Arbeit mit LLMs wie „MANZ Genjus KI“ stellt sich also eine besondere Herausforderung: Die Modelle müssen in der Lage sein, Texte nicht nur zu verstehen, sondern auch präzise und kontextuell passende Antworten zu generieren. Um dies zu gewährleisten, müssen die Inhalte aus juristischer Fachliteratur unter anderem bereits vorab jeweils in kleinere, überschaubare Textpassagen zerlegt und mit umfangreichen Metadaten angereichert werden. Diese Aufgabe ist komplex, aber entscheidend für die Leistungsfähigkeit des Systems.
Die Bedeutung der Granularität bei der Textzerlegung
Die Granularität der Textzerlegung ist ein wesentlicher Faktor für die Effizienz und Präzision von LLMs. Während in traditionellen Rechtsdatenbanken wie der RDB ganze Dokumente als Einheit betrachtet werden, erfordert die Arbeit mit LLMs eine viel feinere Unterteilung. Zeitschriftenbeiträge, Kommentare und Handbücher, Gesetze, Entscheidungen etc. müssen jeweils in kleine Text-Passagen (Chunks) zerlegt werden, um sie effizient mit LLMs verarbeiten zu können. Das hat mehrere Gründe. Zum einen können LLMs nur eine begrenzte Anzahl von Wörtern gleichzeitig verarbeiten. Längere Texte würden diese Grenze überschreiten, was zu einer ungenauen Verarbeitung führen könnte. Das Modell kann so konsistentere und genauere Antworten generieren. Es wird verhindert, dass wichtige Informationen übersehen oder falsch interpretiert werden. Weiters beschleunigt die Zerlegung von Texten den Trainings- und Inferenzprozess des Modells. Kleinere Passagen können schneller analysiert und verarbeitet werden, was die Gesamteffi zienz des Systems erhöht.
Die Rolle der Überlappung bei der Textzerlegung
Ein entscheidender Aspekt bei der Zerlegung von Texten in kleinere Passagen ist aber auch die Frage der Überlappung. Überlappung bedeutet, dass sich die Enden einer Textpassage mit den Anfängen der folgenden Passage überschneiden. Das ist ein wesentlicher Schritt, um die Kohärenz und Genauigkeit der generierten Antworten zu gewährleisten. Ohne Überlappung besteht nämlich die Gefahr, dass das Modell wichtige Informationen verliert, die an den Rändern der Textpassagen vorhanden sind. Angenommen, in einer Textpassage wird ein Gesetz namentlich erwähnt, während in der darauffolgenden Textpassage ein bestimmter Paragraf desselben Gesetzes diskutiert wird, jedoch ohne den Gesetzesnamen erneut zu nennen. Ohne Überlappung würde das Modell die zweite Passage möglicherweise isoliert betrachten und den Bezug zum Gesetz nicht erkennen. Dies könnte dazu führen, dass das Modell eine Antwort generiert, die den Paragrafen zwar korrekt zitiert, aber den Kontext des Gesetzes völlig außer Acht lässt. Die Überlappung der Textpassagen soll sicherstellen, dass solche kritischen Informationen nicht verloren gehen. Das Modell kann dadurch den Zusammenhang zwischen den Textpassagen herstellen und präzise, kontextuell fundierte Antworten generieren. Dies ist besonders wichtig in der juristischen Praxis, wo der Kontext oft entscheidend für die richtige Interpretation eines Textes ist.
Die entscheidende Rolle der Metadaten
Neben der Zerlegung der Texte spielt auch die Anreicherung dieser mit Metadaten eine zentrale Rolle. Juristische Texte sind oft komplex und enthalten eine Vielzahl von Informationen, die nicht unmittelbar im Text enthalten, aber für die richtige Interpretation entscheidend sind. Metadaten helfen daher dem Modell, den Kontext zu verstehen und die Bedeutung des Textes korrekt zu interpretieren. In der juristischen Praxis sind Metadaten besonders wichtig, wie beispielsweise die Gültigkeitsdauer von Texten in Fachpublikationen oder die Zuordnung dieser zu bestimmten Rechtsständen von Normen. „MANZ Genjus KI“ nutzt Metadaten wie das Veröffentlichungsdatum, die Gültigkeitsdauer und Verweise auf andere Rechtsquellen sowie zahlreiche weitere, um sicherzustellen, dass die Antworten nicht nur präzise, sondern auch aktuell sind. Dies verhindert, dass von LLM generierte Zusammenfassungen auf veralteten Informationen basieren, was in der juristischen Praxis schwerwiegende Konsequenzen haben könnte.
„MANZ Genjus KI" - Ihr digitaler Recherche-Assistent
Mit „MANZ Genjus KI“ bieten wir einen Recherche-Assistenten, der Jurist:innen in ihrer täglichen Arbeit unterstützt und ihnen hilft, fundierte Entscheidungen zu treffen. Die Kombination aus LLM-Technologie und der sorgfältigen Aufbereitung der juristischen Texte macht „MANZ Genjus KI“ zu einem leistungsfähigen Assistenten nicht nur für die Recherche, sondern auch für die Erstellung von Zusammenfassungen, Aktennotizen oder Vertragsentwürfen. Jurist:innen können dabei auf eine breite Palette von Informationen aus den zahlreichen Verlagspublikationen von MANZ zugreifen, die durch den RAGAnsatz (Retrieval-Augmented Generation) optimal gefiltert und kontextualisiert werden. Der RAG-Ansatz, eine relativ neue Technologie, ermöglicht es allgemeinen LLMs (chatGPT, Claude oder anderen), unternehmens- oder domänenspezifische Inhalte/Daten effektiv zu nutzen bzw, zu kombinieren. Dabei werden mittels dieser Methode bei „MANZ Genjus KI“ relevante Informationen (Textpassagen) aus dem RDB-Dokumentenbestand abgerufen („retrieval") und in die Antwort des Modells integriert, um präzise und aktuelle Antworten zu liefern. Die Entwicklung einer KI-Lösung mit RAG-Ansatz ist äußerst anspruchsvoll. Dazu bedarf es einer umfangreichen, sorgfältigen Aufbereitung der einzubeziehenden Datenbestände sowie eines tiefgehenden Domänenverständnisses. Neben der technischen Implementierung erfordert der Erfolg auch die kontinuierliche Verbesserung der Datenqualität und die Anpassung an rechtliche Richtlinien. Gelingt dies, wird die Zukunft der juristischen Recherche durch KI nicht nur tiefgreifend verändert, sondern auch mit einem hohen Maß an Effizienz, Präzision und Zeitersparnis gestaltet.
Neugierig geworden? Registrieren Sie sich gleich hier zum Early Access von MANZ Genjus KI.
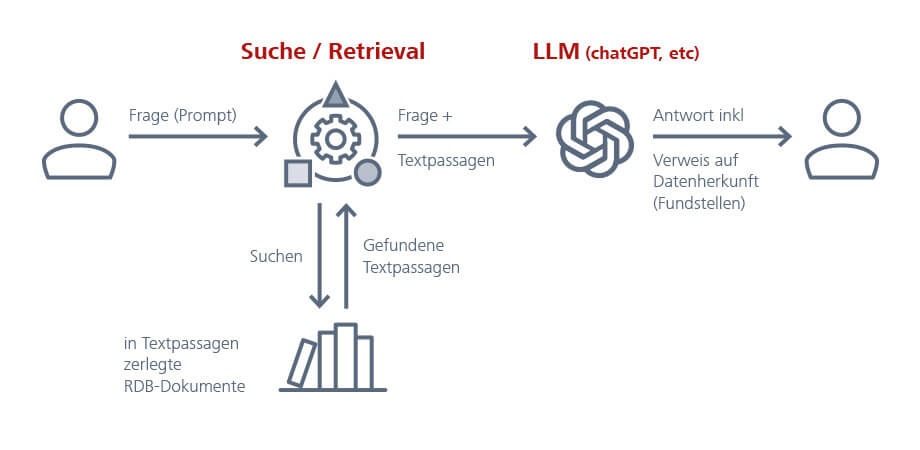
Schematische Darstellung des Retrieval-Augmented-Generation-(RAG)-Ansatzes bei MANZ Genjus KI
Der typische Prozess startet mit einer Benutzeranfrage (links) und besteht aus zwei Schritten: Zuerst erfolgt die Suche oder das Abrufen von Informationen (Mitte). Dabei wird die Anfrage mithilfe natürlicher Sprachverarbeitung in eine Form gebracht, die ein Suchsystem nutzen kann, um passende Textabschnitte aus Dokumenten (zum Beispiel Urteile des Obersten Gerichtshofs) herauszufinden. Anschließend (rechts) werden diese abgerufenen Texte in ein Sprachmodell eingespeist, das daraus eine Antwort auf die ursprüngliche Benutzeranfrage erstellt.
Lesen Sie den vollständigen Artikel in unserer Printausgabe (hier auch als ePaper verfügbar).